Imagine spending hours building the perfect document retrieval pipeline. You’ve got OCR running, layout detection configured, table extraction working, and text chunking perfectly tuned. Then a user searches for “quarterly revenue chart” and your system… returns nothing. Why? Because that beautiful chart in the PDF was never properly extracted, captioned, or indexed.
Enter vision-based retrieval, a paradigm shift that’s turning the document retrieval world upside down. Instead of extracting text and hoping for the best, these models embed entire page images directly, preserving layouts, tables, figures, fonts, and all the visual richness that makes documents actually useful.
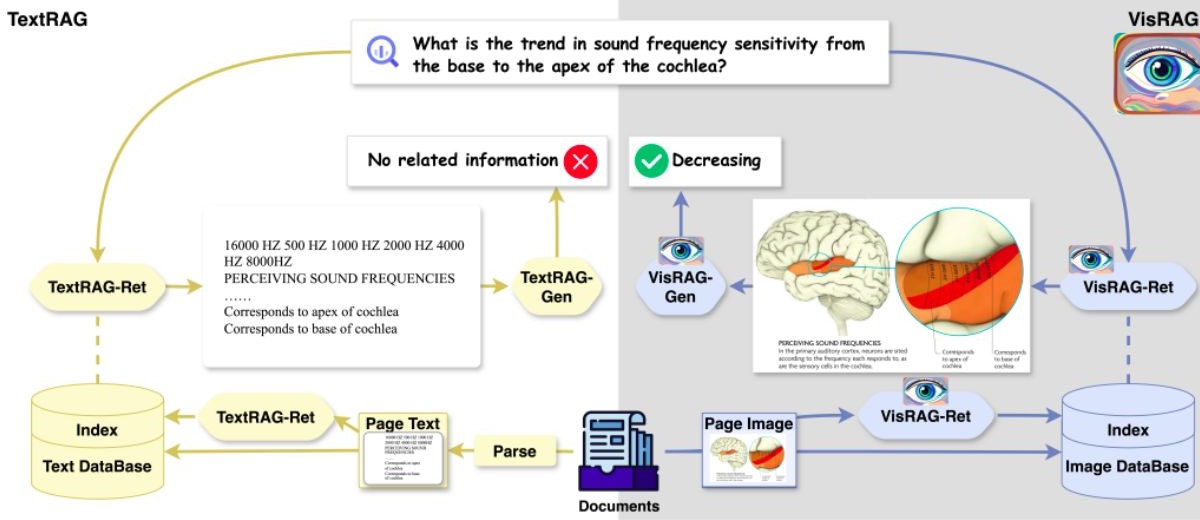
In this Article, we’re diving deep into the world of vision-based document retrieval, exploring the models leading this revolution and the differences between TextRag and VisionRag, as shown in Figure 1.

Figure 1: TextRag vs VisRag [7]
The Problem with Traditional Document Retrieval
The Text-Only
Here’s what happens in a typical document retrieval system:
- OCR Stage: Run optical character recognition on PDFs (crossing fingers it works)
- Layout Analysis: Detect headers, paragraphs, tables, and figures
- Extraction Pipeline: Pull out text, attempt to caption images/tables with VLMs
- Chunking Strategy: Split text into meaningful chunks (good luck with that)
- Text Embedding: Map chunks to vector space using models like BGE-M3
- Storage & Indexing: Store everything in a vector database
Each step is a potential failure point. OCR struggles with handwriting and complex layouts. Tables get flattened into incomprehensible text. Figures lose their visual meaning when reduced to text captions.
Single-Vector vs Multi-Vector Retrieval: Understanding the Paradigms
Before diving into the models, it’s crucial to understand the two fundamental approaches to vector-based retrieval.
Single-Vector Retrieval
How It Works: Each document (or document page) is encoded into a single dense vector representation, typically ranging from 128 to 2048 dimensions.
Advantages:
- Storage Efficient: One vector per document means minimal storage overhead
- Fast Retrieval: Simple cosine similarity or dot product operations
- Scalable: Works well with millions of documents using HNSW or IVF indexes
- Simpler Infrastructure: Standard vector databases handle this natively
Limitations:
- Information Compression: All document information squeezed into one vector
- Less Granular: Can’t capture fine-grained relationships between query terms and document regions
- Context Loss: Struggles when queries relate to specific document sections
Multi-Vector Retrieval
How It Works: Documents are encoded into multiple vectors—one per visual patch, text token, or semantic unit. Query terms interact with each vector independently, and scores are aggregated (typically using MaxSim operation from ColBERT [1]).
Advantages:
- Rich Interaction: Each query term finds its best matching document patch
- Preserves Granularity: Maintains spatial and semantic relationships within documents
- Superior for Complex Queries: Excels when queries reference specific visual elements, tables, or sections
- Better for Visual Content: Can match query terms to exact locations (chart legends, table cells, figure captions)
Limitations:
- Storage Overhead: 128x to 1024x more vectors per document
- Slower Retrieval: Requires MaxSim computation across all patch vectors
- Complex Infrastructure: Needs specialized indexing (e.g., PLAID index [2])
- Higher Memory: Significant RAM requirements for large document collections
The Players: Vision-Based Retrieval Models
1. ColPali: The Pioneer
Reference: Faysse et al., 2024 [3]
What It Is: ColPali (Contextualized Late Interaction over PaliGemma) kicked off the vision retrieval revolution architecture as shown in Figure 2, demonstrating that vision-language models could outperform traditional text-extraction pipelines in visually enriched documents without any preprocessing.

Figure 2: ColPali Architecture [3]
Architecture:
- Foundation Model: PaliGemma-3B (Google’s vision-language model)
- Vision Encoder: SigLIP-So400m (400M parameters)
- Language Model: Gemma-2B
- Image Patches: 1024 patches per page
- Embedding Dimension: 128-dim per patch
- Total Parameters: ~3B
Key Features:
- Late Interaction Mechanism: Borrowed from ColBERT[1], enables rich query-document interaction at the patch level
- Multi-Vector Output: 1024 vectors per page for granular matching
- Zero Preprocessing: Direct image embedding without OCR or layout analysis
- Projection Layer: Maps vision-language embeddings to retrieval-optimized space
2. ColQwen2: The Efficiency King
Reference: Faysse et al., 2024 [4]
What It Is: The next evolution of ColPali, built on Alibaba’s Qwen2-VL model, offering superior efficiency and performance.
Architecture:
- Foundation Model: Qwen2-VL-2B
- Vision Encoder: Enhanced ViT with dynamic resolution support
- Language Model: Qwen2-2B
- Image Patches: 768 patches per page (vs 1024 in ColPali)
- Embedding Dimension: 128-dim per patch
- Total Parameters: ~2B
Key Features:
- Dynamic Resolution: Handles varying image sizes without aspect ratio distortion using NaViT technique
- Better Compression: 25% fewer patches with no performance loss
- Improved Training: Enhanced hard negative mining and batch construction
- Multilingual: Native support for multiple languages through Qwen2 backbone
3. Jina CLIP v2: The Multilingual Champion
Reference: Koukounas et al., 2024 [5]
What It Is: A CLIP-style contrastive model that excels at both text and image retrieval with exceptional multilingual capabilities.
Architecture:
- Text Encoder: Jina-XLM-RoBERTa (561M parameters)
- Vision Encoder: EVA02-L14 (304M parameters)
- Image Resolution: 512×512 pixels (4x area of CLIP v1)
- Embedding Dimension: 1024-dim (truncatable via Matryoshka)
- Total Parameters: 865M
Key Features:
- 89 Languages: Trained on multilingual data covering major world languages
- Matryoshka Representations: Truncate embeddings from 1024 to 64 dimensions with 99% performance retention at 75% compression
- Single-Vector Output: Simpler storage and retrieval than multi-vector approaches
- High Resolution: 512×512 input enables better detail capture
- Dual-Pool Architecture: Task-specific pooling strategies for optimal performance
4. Nomic Embed Vision: The Unified Space
Reference: Nomic AI, 2024 [6]
What It Is: The first open-weights model to create a truly unified latent space for text and vision, where text embeddings and image embeddings are genuinely compatible.
Architecture:
- Vision Encoder: Aligned with Nomic Embed Text encoder
- Text Encoder: NomicBERT with rotary position embeddings
- Embedding Dimension: 768-dim unified space
- Training Strategy: Contrastive alignment between modalities
Key Features:
- True Multimodal Space: Unlike CLIP models, maintains strong text-only retrieval performance
- Unified Embeddings: Text and vision in same latent space without compromise
- Rotary Position Embeddings: Enables better long-context understanding
- Dimensionality Options: Support for variable embedding sizes
Future is Visual: What’s Next?
Longer Context: Models handling entire multi-page documents as single images, moving beyond page-by-page retrieval to document-level understanding.
Better Efficiency: New architectures reduce storage and compute costs through improved compression techniques, sparse attention mechanisms, and optimized indexing structures.
Specialized Models: Domain-specific vision retrievers fine-tuned for medical imaging reports, legal documents with complex formatting, and financial statements with tables and charts.
Cross-Document Visual Reasoning: Models that can find relationships between visual elements across multiple documents, enabling questions like “show me all charts with similar trends.”
Important Note:
We are going to use and adopt this Paradigm or technique in our projects that requires retrieving images given a text at Intixel.
References
[1] Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR ’20: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 39-48. https://arxiv.org/abs/2004.12832
[2] Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., & Zaharia, M. (2022). ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. NAACL 2022. https://arxiv.org/abs/2112.01488
[3] Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., & Colombo, P. (2024). ColPali: Efficient Document Retrieval with Vision Language Models. arXiv preprint arXiv:2407.01449. https://arxiv.org/abs/2407.01449
[4] Faysse, M., Sibille, H., Viaud, G., Wu, T., Omrani, B., Hudelot, C., & Colombo, P. (2024). ColQwen2: Improving Vision-Based Document Retrieval. HuggingFace Model Card. https://huggingface.co/vidore/colqwen2-v0.1
[5] Koukounas, K., Mastrapas, G., Günther, M., Wang, B., Kacprzyk, J., Jina AI. (2024). Jina CLIP v2: Multilingual Multimodal Embeddings for Text and Images. arXiv preprint arXiv:2412.08802. https://arxiv.org/abs/2412.08802
[6] Nomic AI. (2024). Nomic Embed Vision: Expanding Nomic Embed to Vision. Technical Report. https://blog.nomic.ai/posts/nomic-embed-vision
[7] Yu, S., Tang, C., Xu, B., Cui, J., Ran, J. F., Yan, Y., Liu, Z., Wang, S., Han, X., Liu, Z., & Sun, M. (2024). VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents. arXiv preprint arXiv:2410.10594. https://arxiv.org/abs/2410.10594